



Characters, Symbols and the Unicode Miracle
영어공부 겸 코딩 유튜브 해석~
UTF-8 is perhaps the best hack, the best single thing that's used
that can be written down on the back of a napkin, and that's how was it was put together.
The first draft of UTF-8 was written on the back of a napkin in a diner
and it's just such an elegant hack that solved so many problems and I absolutely love it.
UTF-8은 간단하지만 강력한 문자 인코딩 방식으로, 처음 초안은 식당에서 냅킨에 적혔다고 전해진다.
이 방식은 여러 문제를 우아하게 해결했다.
Back in the 1960s, we had teleprinters, we had simple devices where you type a key and it sends some numbers and the same letter comes out on the other side, but there needs to be a standard so in the mid-1960s America, at least, settled on ASCII, which is the American Standard Code for Information Interchange, and it's a 7-bit binary system, so each letter you type in gets converted into 7 binary numbers and sent over the wire.
1960년대에는 전신 타자기(TelePrinter)와 같은 장치를 사용했는데,
키를 누르면 몇몇 숫자들을 보내서 수신하는 곳에서는 동일한 숫자가 나오는 식이었다.
하지만 1960년대 중반 미국에서는 정보 교환을 위한 표준이 필요해서, ASCII라는 7비트 문자 표준을 만들었다.
이를 통해 7비트로 이루어진 숫자로 데이터를 효율적으로 전송할 수 있었다.
Now that means you can have numbers from 0 to 127.
They sort of moved the first 32 for control codes and less important stuff for writing,
things like like "go down a line" or backspace.
And then they made the rest characters. They added some numbers, some punctuation marks.
그렇다는 건, 각 문자는 7개의 이진수로 변환되어 전송되었고, 총 0~127까지 숫자를 표현할 수 있었다는 것이다.
처음 32개는 백스페이스나 줄바꿈 등을 나타내는 제어 코드로 사용하고,
나머지는 문자, 숫자, 구두점 등을 할당해서 사용했다.

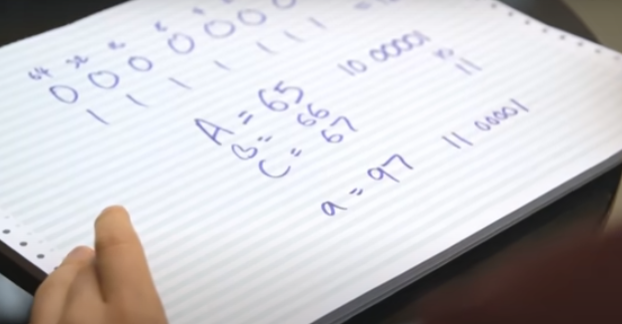
They did a really clever thing, which is that they made 'A' 65 which, in binary—
find 1, 2, 4, 8, 16, 32, 64—in binary, 65 is 1000001,
which means that 'B' is 66, which means you've got 2 in binary just here. C, 67, 3 in binary.
So you can look at a 7-bit binary character and just knock off the first two digits
and know what its position in the alphabet is.
Even cleverer than that, they started lowercase 32 later, which means that lowercase 'a' is 97—1100001.
특히 ‘A’를 65로 지정한 것은 굉장히 영리한 선택이었다.
대문자 A와 소문자 a는 각각 65와 97, B와 b는 66과 98 과 같은 패턴인데,
32 차이가 나기 때문에 앞에서 두번째 자리를 1로 두냐 0으로 두냐로 굉장히 효율적으로 구분할 수 있게 됐다.
Anything that doesn't fit into that is probably a space, which conveniently will be all zeroes,
or some kind of punctuation mark. Brilliant, clever, wonderful, great way of doing things,
and that became the standard, at least in the English-speaking world.
공백이나 구두점 같은 기호들은 그 범위에 맞지 않지만, 최소한 영어권에서는 표준이 되었다.
As for the rest of the world, a few of them did versions of that,
but you start getting into other alphabets, into languages that don't really use alphabets at all.
They all came up with their own encoding, which is fine.
영어권 외의 국가들은 알파벳을 아예 사용하지 않는 나라들도 있었기 때문에 자체 문자 인코딩을 개발했다.
And then along come computers, and, over time, things change.
We move to 8-bit computers, so we now have a whole extra number at the start just to confuse matters,
which means we can go to 256! We can have twice as many characters!
그리고 컴퓨터가 나오고, 상황이 많이 바뀌었다.
8비트 컴퓨터가 등장하고, 여러 가지 문자들을 지원할 수 있게 바뀌어야만 했다.
그렇다는 건, 0부터 127에서, 256까지 확장할 수 있게 됐다는 의미였다.
And, of course, everyone settled on the same standard for this, because that would make perfect s—
No. None of them did.
그리고 당연히 전세계의 모두가... 동일한 표준에 동의하지는 못했다.
All the Nordic countries start putting Norwegian characters and Finnish characters in there.
Japan just doesn't use ASCII at all.
Japan goes and creates its own multibyte encoding with more letters and more characters
and more binary numbers going to each individual character.
All of these things are massively incompatible.
모든 북유럽 국가들은 거기에 노르웨이 문자와 핀란드 문자를 넣기 시작했고,
일본은 아예 ASCII를 전혀 사용하지 않았다. 일본은 더 많은 글자와 더 많은 문자를 포함하고,
각 개별 문자에 더 많은 이진수가 할당되는 자체 멀티바이트 인코딩을 만들어 버렸다.
이러한 것들은 서로 전혀 호환되지 않았다.
Japan actually has three or four different encodings, all of which are completely incompatible with each other.
So you send a document from one old-school Japanese computer to another,
it will come out so garbled that there is even a word in Japanese for "garbled characters,"
which is—I'm probably mispronouncing this—but it's "mojibake."
일본에는 실제로 세 가지 또는 네 가지의 서로 완전히 호환되지 않는 인코딩이 존재했다.
그래서 구식 일본 컴퓨터에서 다른 구식 일본 컴퓨터로 문서를 보내면,
글자가 너무 심하게 깨져서 일본어에는 “문자가 깨지는 현상”을 뜻하는 단어까지 있다. = 모지바케
처음에 일본어에서 문자 깨짐을 文字化(もじばけ) 라고 불렀는데,
이게 영어권으로 수출되어 이제는 문자가 깨지는 현상을 mojibake 라고 한다고 한다ㅋㅋㅋ
It's a bit of a nightmare, but it's not bad,
because how often does someone in London have to send a document to a completely incompatible and unknown computer at another company in Japan?
In those days, it's rare. You printed it off and you faxed it.
굉장히 절망적인 상황이었지만 나쁘진 않았다.
런던에 있는 누군가가 완전히 호환되지도 않고 알 수도 없는 일본에 있는 다른 회사에 문서를 보낼 일이 얼마나 있겠냐고?
그때는 그럴 일이 거의 없었다. 그냥 프린트해서 팩스로 보내면 될 일이었다.
And then the World Wide Web hit, and we have a problem,
because suddenly documents are being sent from all around the world all the time.
So a thing is set up called the Unicode Consortium.
In what I can only describe as a miracle, over the last couple of decades, they have hammered out a standard.
Unicode now have a list of more than a hundred thousand characters that covers everything you could possibly want to write in any language—English alphabet, Cyrillic alphabet, Arabic alphabet, Japanese, Chinese, and Korean characters.
그리고 월드 와이드 웹의 등장으로 전 세계로 언제든 문서를 주고받아야 하는 상황이 되면서,
Unicode 컨소시엄이 설립되어 몇십년 동안의 노력 끝에 표준을 확립할 수 있었다.
유니코드는 이제 어떤 언어로든 쓰고 싶은 언어로 된 10만 개의 문자를 표현할 수 있다.
영어 알파벳, 키릴 알파벳, 아라비아 알파벳, 일본어, 중국어, 한글까지..
What you have at the end is the Unicode Consortium assigning 100,000+ characters to 100,000 numbers.
They have not chosen binary digits. They have not chosen what they should be represented as.
All they have said is that THAT Arabic character there, that is number 5,700-something,
and this linguistic symbol here, that's 10,000-something.
유니코드 컨소시엄은 10만 개가 넘는 문자를 10만 개의 숫자에 할당했지만 이진 표현은 정하지 않았다.
단순히 저 아라비아 문자는 5천7백 몇번...이 문자는 만 몇번... 이런 식이었다.
I have to simplify massively here because there are about,
of course, five or six incompatible ways to do this,
but what the web has more or less settled on is something called "UTF-8."
There are a couple of problems with doing the obvious thing, which is saying,
"OK. We're going to 100,000. That's gonna need, what... to be safe, that's gonna need 32 binary digits to encode it."
각 숫자에 할당된 이진 표현을 구현하는 서로 호환되지 않는 방법이 다섯, 여섯 가지 정도는 있었다.
하지만 웹에서 대체로 정착한 방식은 UTF-8이다. 당연해 보이는 방법에도 몇 가지 문제가 있었다.
예를 들어,
"좋아요, 우리는 이제 10만 개 문자가 필요합니다. 안전하게 하려면… 32비트 이진 숫자가 필요하겠네요." 이런 느낌이다.
They encoded the English alphabet in exactly the same way as ASCII did. 'A' is still 65.
So if you have just a string of English text, and you're encoding it at 32 bits per character,
you're gonna have about 20-something... 26? Yeah. 26, 27 zeroes and then a few ones for every single character.
That is incredibly wasteful.
Suddenly every English language text file takes four times the space on disk.
그런데 그 방식은 영어 알파벳을 ASCII와 정확히 같은 방식으로 인코딩했다.
예를 들어 'A'는 여전히 65이고, 만약 영어 텍스트만 있는 문자열을 32비트로 문자 하나하나 인코딩한다면,
각 문자마다 20몇 개… 26? 네, 26~27개의 0과 몇 개의 1이 붙게 된다. 이건 굉장히 자원 낭비가 심한 방식이다.
갑자기 모든 영어권 문자 파일이 디스크에 공간이 4배 더 필요하게 된 것이다.
So, problem 1: you have to get rid of all the zeroes in the English text.
Problem 2: there are lots of old computer systems that interpret 8 zeroes in a row,
a NULL, as "this is the end of the string of characters."
so if you ever send 8 zeroes in a row, they just stop listening.
They assume the string has ended there, and it gets cut off,
so you can't have 8 zeroes in a row anywhere.
OK. Problem number 3: it has to be backwards-compatible.
You have to be able to take this Unicode text and chuck it into something that only understands basic ASCII,
and have it more or less work for English text.
첫번째 문제는, 영문자에서 모든 0을 제거해야 한다는 것이다.
두 번째는, 8개의 나열된 0을 NULL(문자열의 끝을 나타냄)로 해석하는 오래된 컴퓨터가 많이 있었기 때문에,
0000 0000 을 보내면 그 다음의 문자는 더이상 읽지 않게 되는 문제가 있었다.
그래서 문자를 보낼 때 어디에도 8개의 0을 포함시키면 안 됐다.
세 번째 문제는 이전 버전과의 호환성이다. 유니코드 문자를 받아서 기본 ASCII만 이해하는 어딘가에 입력했을 때,
최소한, 적어도 영어 텍스트라면 어느 정도 동작해야 한다.

UTF-8 solves all of these problems and it's just a wonderful hack.
It starts by just taking ASCII.
If you have something under 128, that can just be expressed as 7 digits,
you put down a zero, and then you put the same numbers that you would otherwise,
so let's have that 'A' again—there we go!
That's still 'A.' That's still 65. That's still UTF-8-valid, and that's still ASCII-valid. Brilliant.
OK. Now let's say we're going above that.
UTF-8은 이러한 모든 문제를 잘 해결해냈다. 그냥 ASCII를 채택하는 것으로 시작했는데,
128 미만의 어떤 값이 있다면 7비트로 표현될 수 있고, 아까처럼 0을 하나 쓴 뒤,
0 1000001 이라고 하면 여전히 A를 표현할 수 있다. 이렇게 하면 UTF-8과도 호환되고, ASCII에도 호환된다.
Now you need something that's gonna work more or less for ASCII, or at least not break things, but still be understood.
So what you do is you start by writing down "110."
이제 최소한 ASCII는 만족하면서 어떤 것도 망가뜨리지 않고 여전히 해석될 수 있는 게 필요하다.
그러면, 110을 작성하면서 시작할 수 있다.

This means this is the start of a new character, and this character is going to be 2 bytes long.
Two ones, two bytes, a byte being 8 characters.
And you say on this one, we're gonna start it with "10," which means this is a continuation,
and at all these blank spaces, of which you have 5 here and 6 here, you fill in the other numbers,
and then when you calculate it, you just take off those headers,
and it understands just as being whatever number that turns out to be.
That's probably somewhere in the hundreds.
110은 새로운 문자가 시작된다는 것을 나타내고, 이 문자는 2바이트의 길이를 갖는다.
앞에 두 개의 1은 2바이트를 의미하고, 한 바이트는 8비트가 된다.
그리고 다음 바이트에서는 10으로 시작하게 되는데, 이것은 이 바이트가 "이어지는" 바이트임을 의미한다.
그리고 공백으로 표시된 부분(위 이미지 기준 왼쪽에서는 5비트, 오른쪽에서는 6비트)에 나머지 숫자를 채워 넣는다.
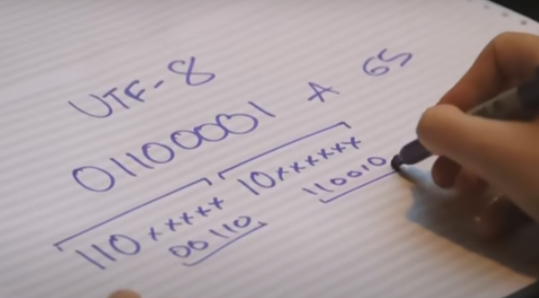
그 후에 계산할 때는 이런 헤더 부분(110, 10)을 제거하고,
남은 비트들을 하나의 숫자로 인식하게 되며 그 수는 수백 단위를 표현할 수 있다.
That'll do you for the first 4,096. What about above that?
그걸로 처음 4,096까지는 충분히 표현할 수 있게 된다. 하지만 그 이상이 되면 어떨까?

Well, above that you go "1110," meaning there are three bytes in this—three ones, three bytes—
with two continuation bytes.
So now you have 1, 2, 3, 4, 10, 16 spaces. You want to go above that? You can.
This specification goes all the way to "1111110x" with this many continuation bytes after it.
1110 이라고 적으면, 3바이트를 의미한다. 1이 3개, 3byte, 그리고 두 개의 연속 바이트.(=10)가 있다.
그래서 이제 16개의 빈칸이 생긴다. 그 이상으로도 얼마든지 확장할 수 있다.
1111110x 까지 갈 수 있고, 그 뒤에 수많은 연속 바이트들이 올 수 있게 된다.
It's a neat hack that you can explain on the back of a napkin or a bit of paper.
It's backwards-compatible. It avoids waste. At no point will it ever, ever, ever send 8 zeroes in a row,
and, really, really crucially, the one that made it win over every other system is that you can move backwards and forwards really easily.
냅킨이나 종이 조각만 있어도 설명할 수 있는 깔끔한 방법이다.
이전 버전과 호환되고, 낭비도 줄일 수 있고, 어떠한 경우에도 0을 8개 연속해서 보낼 일이 없어진다.
그리고 결정적으로, 다른 모든 시스템보다 우위를 점하게 만든 부분은
문자열 내에서 앞이나 뒤로 매우 쉽게 이동할 수 있다는 점이다.
You do not have to have an index of where the character starts.
If you are halfway through a string and you wanna go back one character, you just look for the previous header.
And that's it, and that works, and, as of a few years ago, UTF-8 beat out ASCII and everything else as, for the first time,
the dominant character encoding on the web.
어디가 문자의 시작점의 인덱스를 기억해놓을 필요가 없다.
만약 문자열의 중간 부분에 있다가 하나의 문자 뒤로 이동하고 싶으면, 그냥 앞 부분의 헤더를 확인하면 된다.
그게 전부이며 잘 작동한다. 그리고 몇년 전부 UTF-8이 ASCII와 다른 모든 것을 제치고 지배적인 문자 인코딩이 되었다.
We don't have that mojibake that Japanese has.
We have something that nearly works, and that is why it's the most beautiful hack that I can think of
that is used around the world every second of every day.
일본에서처럼 모지바케가 발생하지 않는다.
거의 잘 작동하는 무언가가 되었고, 가장 아름다운 hack이자, 매일 매 초 전 세계에서 사용되는 이유이다.

'TIL > ETC' 카테고리의 다른 글
| nginx http2 설정 (feat. http/1.x 부터 http/3) (0) | 2025.08.05 |
|---|---|
| 일렉트론 자동 업데이트 설정하기 (electron auto-updater) (0) | 2025.07.21 |
| fail2ban Tutorial (1) | 2025.07.17 |
